
pythonの前処理でdropを使って重複している列を削除する方法について
動作環境:Win10、jupyter notebook
なぜ削除するのか
機械学習させる時に、重複や似たデータがあると学習精度が落ちることがあるからです。(多重共線性)
処理
下記データはトヨタと日産の1月25日の歩み値データです。
列「day」が重複しているので、「day_y」の列を削除します。

import pandas as pd
pip install openpyxl
df = pd.read_csv(‘元データファイルのパス/ファイル名.csv’)
df1 = df.drop(‘day’ ,axis=1)
結果
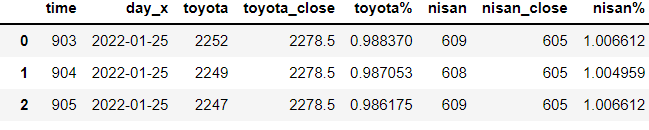
「day_y」の列がなくなりました。
axis=の1を0にすると、行の削除